2.5鼎鼎大名的詞網(WordNet)
WordNet是語意導向的英文字典,有點類似傳統常見的索引典(thesaurus),不過擁有更豐富的結構。NLTK所提供的WordNet擁有15萬字以及11萬個同義詞組。接下來我們會先來看看同義詞,然後學著如何存取WordNet。
字義與同義詞
讓我們來看看下頭的例子吧!在這裡(1a)的「motorcar」被(1b)的「automobile」所取代,但其實兩個句子的意思是沒有什麼改變的:
(1)
a.
Benz is credited with the invention of the motorcar.
b.
Benz is credited with the invention of the automobile.
由於除了「motorcar 」與「automobile 」外,句子其它的部分都完全一樣,所以我們可以下一個結論,就是這兩個字為「同義」!以下將利用WordNet來協助我們繼續探索這類型的字詞吧。
>>> from nltk.corpus import wordnet as wn >>> wn.synsets('motorcar') [Synset('car.n.01')] |
因此「motorcar」是屬於同義詞組「Synset('car.n.01') 」中的一個,「'car.n.01'」意謂car的第一個名詞字義,此外我們也可以相反過來查詢:
| >>> wn.synset('car.n.01').lemma_names ['car', 'auto', 'automobile', 'machine', 'motorcar'] |
當然!同義詞組裡的每個字可能都各自有不同字義(如car還可能代表火車車廂、電梯之類的),但是我們關注的是有哪些字可以代表同一種字義,就像上面我們看到的同義詞組(synset)。同義詞組還會提供一些簡單的定義說明與例句唷!
| >>> wn.synset('car.n.01').definition 'a motor vehicle with four wheels; usually propelled by an internal combustion engine' >>> wn.synset('car.n.01').examples ['he needs a car to get to work'] |
雖然這些定義說明有助於身為人類的我們去理解這些詞組的意義,但對於系統與程式來說同義詞組的字詞們(words)才比較重要。為了避免混淆,我們把這些字標示得很清楚(如car.n.01.automobile或car.n.01.motorcar等),這些詞組內的組合叫做「詞元(lemma)」。我們可以特定選取某個假定的同義詞組中的所有lemmas、查詢特定的lemma、由lemma擷取相對應的詞組名稱、取出lemma的字詞等。
| >>> wn.synset('car.n.01').lemmas [Lemma('car.n.01.car'), Lemma('car.n.01.auto'), Lemma('car.n.01.automobile'), Lemma('car.n.01.machine'), Lemma('car.n.01.motorcar')] >>> wn.lemma('car.n.01.automobile') Lemma('car.n.01.automobile') >>> wn.lemma('car.n.01.automobile').synset Synset('car.n.01') >>> wn.lemma('car.n.01.automobile').name 'automobile' |
不過不是每個詞組都像「automobile」與「motorcar」擁有這麼簡單明確的字義只屬於一個同義詞組,換作是成「car」就複雜多了,他身兼五組同義詞組:
| >>> wn.synsets('car') [Synset('car.n.01'), Synset('car.n.02'), Synset('car.n.03'), Synset('car.n.04'), Synset('cable_car.n.01')] >>> for synset in wn.synsets('car'):... print synset.lemma_names... ['car', 'auto', 'automobile', 'machine', 'motorcar'] ['car', 'railcar', 'railway_car', 'railroad_car'] ['car', 'gondola'] ['car', 'elevator_car'] ['cable_car', 'car'] |
當然你可以用更方便的方式去存取所有有關car的lemma:
| >>> wn.lemmas('car') [Lemma('car.n.01.car'), Lemma('car.n.02.car'), Lemma('car.n.03.car'), Lemma('car.n.04.car'), Lemma('cable_car.n.01.car')] |
WordNet的階層結構
Wordnet的同義詞組對應到的是一個個抽象的概念,並非是明確的對應到某個字詞。只是呢,這些概念透過階層的方式連結在一起,有一些概念很普遍,像是一些實體、狀態或事件,稱作「unique beginners」或「root synsets(根同義詞組)」。當然也會一些相當專門的詞,如gas guzzler(耗油車)與 hatchback(艙蓋式汽車)等。底下是一個這種階層概念的圖例。
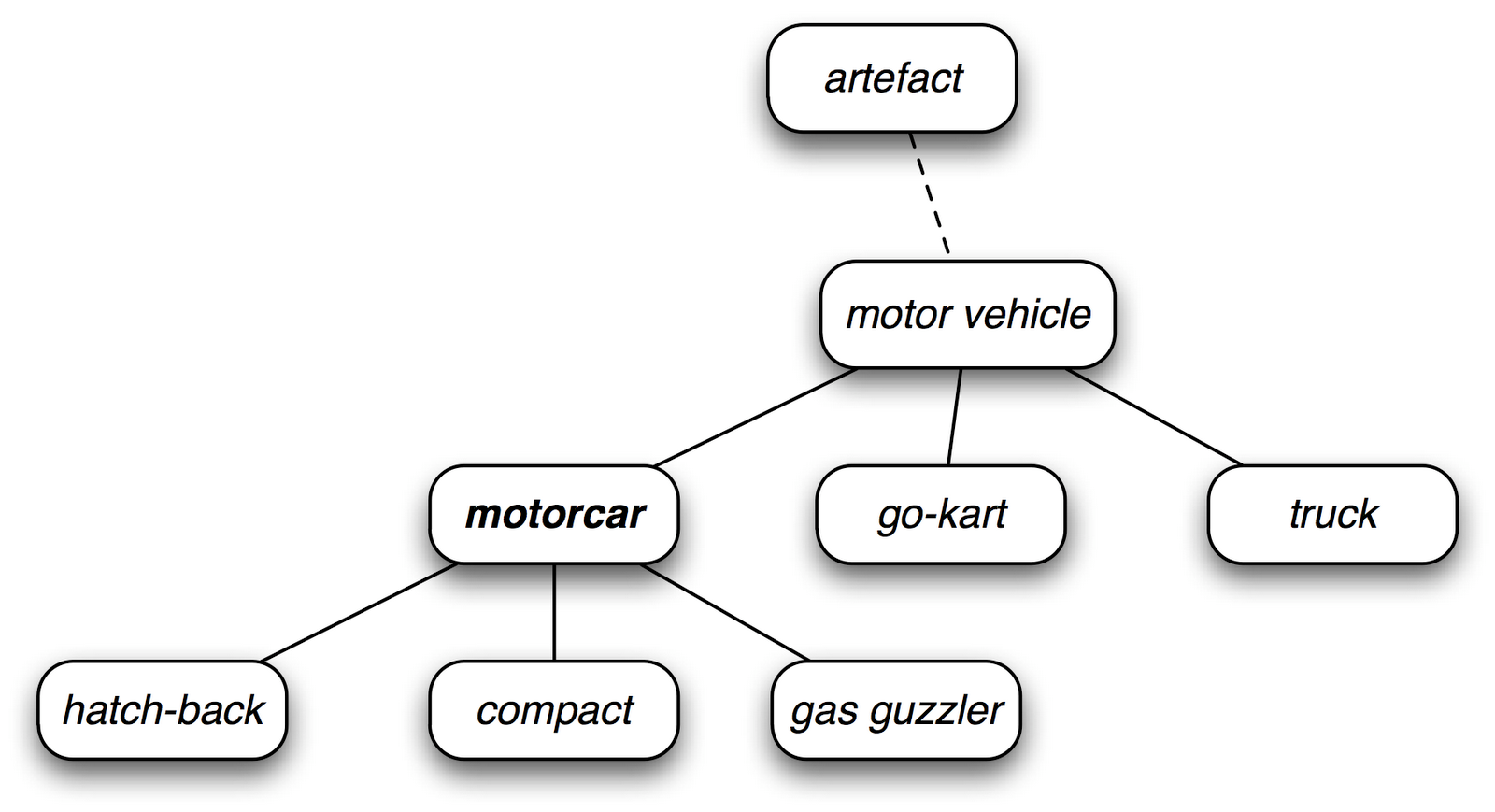
WordNet利用這種方法把每個概念連結在一起,像是上圖就是「motorcar」的位置,其實我們就利用這種關連來存取它底下的字詞(所謂的下位詞,hyponyms)
>>> motorcar = wn.synset('car.n.01') >>> types_of_motorcar = motorcar.hyponyms() >>> types_of_motorcar[26] Synset('ambulance.n.01') >>> sorted([lemma.name for synset in types_of_motorcar for lemma in synset.lemmas]) ['Model_T', 'S.U.V.', 'SUV', 'Stanley_Steamer', 'ambulance', 'beach_waggon', 'beach_wagon', 'bus', 'cab', 'compact', 'compact_car', 'convertible', 'coupe', 'cruiser', 'electric', 'electric_automobile', 'electric_car', 'estate_car', 'gas_guzzler', 'hack', 'hardtop', 'hatchback', 'heap', 'horseless_carriage', 'hot-rod', 'hot_rod', 'jalopy', 'jeep', 'landrover', 'limo', 'limousine', 'loaner', 'minicar', 'minivan', 'pace_car', 'patrol_car', 'phaeton', 'police_car', 'police_cruiser', 'prowl_car', 'race_car', 'racer', 'racing_car', 'roadster', 'runabout', 'saloon', 'secondhand_car', 'sedan', 'sport_car', 'sport_utility', 'sport_utility_vehicle', 'sports_car', 'squad_car', 'station_waggon', 'station_wagon', 'stock_car', 'subcompact', 'subcompact_car', 'taxi', 'taxicab', 'tourer', 'touring_car', 'two-seater', 'used-car', 'waggon', 'wagon'] |
相反地,我們也可以存取上位詞(hypernyms),有一些字有多種路徑,因為它們可以被歸屬到一個以上的概念下面。像是以下的例子,「motorcar」的路徑會有兩種,因為在「wheeled_vehicle.n.01」這裡時可能被歸屬到車輛(vehicle)、或是容器(container)。
>>> motorcar.hypernyms() [Synset('motor_vehicle.n.01')] >>> paths = motorcar.hypernym_paths() >>> len(paths) 2 >>> [synset.name for synset in paths[0]] ['entity.n.01', 'physical_entity.n.01', 'object.n.01', 'whole.n.02', 'artifact.n.01', 'instrumentality.n.03', 'container.n.01', 'wheeled_vehicle.n.01', 'self-propelled_vehicle.n.01', 'motor_vehicle.n.01', 'car.n.01' ]>>> [synset.name for synset in paths[1]] ['entity.n.01', 'physical_entity.n.01', 'object.n.01', 'whole.n.02', 'artifact.n.01', 'instrumentality.n.03', 'conveyance.n.03', 'vehicle.n.01', 'wheeled_vehicle.n.01', 'self-propelled_vehicle.n.01', 'motor_vehicle.n.01', 'car.n.01'] |
我們也可以直接找出最根本的上位詞(root hypernyms):
>>> motorcar.root_hypernyms() [Synset('entity.n.01')] |
註:你也可以試試看方便的WordNet圖形化介面:nltk.app.wordnet()
更多的詞彙關係(More Lexical Relations)
其實上位詞(hypernyms)與下位詞( hyponyms)就是這邊要談的「詞彙關係(lexical relations)」,因為它們能把一個同義詞組(synset)與另一個做連結。這兩種關係顯示了在階層關係中的向上與向下的從屬關連。另一種關連則是部分(meronyms)與全體(holonyms),從下例來說:透過「part_meronyms()」就是可以發現一棵樹是由樹幹(trunk)、樹冠(crown)等等所組成的。透過「substance_meronyms()」可以發現一棵樹會包含樹心材(heartwood )與邊材(sapwood)等物質組成。也可以利用「member_holonyms()」找出一群樹可以產生什麼?(森林,forest):
>>> wn.synset('tree.n.01').part_meronyms() [Synset('burl.n.02'), Synset('crown.n.07'), Synset('stump.n.01'), Synset('trunk.n.01'), Synset('limb.n.02')] >>> wn.synset('tree.n.01').substance_meronyms() [Synset('heartwood.n.01'), Synset('sapwood.n.01')] >>> wn.synset('tree.n.01').member_holonyms() [Synset('forest.n.01')] |
有時候我們必須去釐清一些較為複雜的字詞含意,像是這邊的「mint」,它擁有幾個相近的字義,如同我們在下例看到,把幾組字義先查詢出來之後發現,「mint.n.04」是「mint.n.02」的一部份(part)、同時也是「mint.n.05」的物質物件(substance):
>>> for synset in wn.synsets('mint', wn.NOUN):... print synset.name + ':', synset.definition... batch.n.02: (often followed by `of') a large number or amount or extent mint.n.02: any north temperate plant of the genus Mentha with aromatic leaves and small mauve flowers mint.n.03: any member of the mint family of plants mint.n.04: the leaves of a mint plant used fresh or candied mint.n.05: a candy that is flavored with a mint oil mint.n.06: a plant where money is coined by authority of the government >>> wn.synset('mint.n.04').part_holonyms() [Synset('mint.n.02')] >>> wn.synset('mint.n.04').substance_holonyms() [Synset('mint.n.05')] |
此外還有一些動詞的關係,像是「走路,walking 」就包括了「踏,stepping」的含意,當然!有一些動詞會包含許多含意在裡頭:
>>> wn.synset('walk.v.01').entailments() [Synset('step.v.01')] >>> wn.synset('eat.v.01').entailments() [Synset('swallow.v.01'), Synset('chew.v.01')] >>> wn.synset('tease.v.03').entailments() [Synset('arouse.v.07'), Synset('disappoint.v.01')] |
相反地,我們也可以利用詞元lemma去找出一些反義字(antonymy):
>>> wn.lemma('supply.n.02.supply').antonyms() [Lemma('demand.n.02.demand')] >>> wn.lemma('rush.v.01.rush').antonyms() [Lemma('linger.v.04.linger')] >>> wn.lemma('horizontal.a.01.horizontal').antonyms() [Lemma('vertical.a.01.vertical'), Lemma('inclined.a.02.inclined')] >>> wn.lemma('staccato.r.01.staccato').antonyms() [Lemma('legato.r.01.legato')] |
現在你看到了不少詞彙關係囉~不過其實還有許多方法可以去善用WordNet的synset,你可以試著dir()看看,例如:dir(wn.synset('harmony.n.02'))
語意相似性(Semantic Similarity)
我們現在已經瞭解到一組組的synset是一個由各種詞彙關係所連結起來的複雜網絡,只要給我們一個特定的synset,就能夠在WordNet中找到各種相關意義。這種工具能夠有效地將文本中的內容進行語意化的處理,如我們的目標是找出所有與「vehicle」相關的字,而文本中的「豪華轎車(limousine)」則會被找出來。
回想一下,每synset都有一個或多個上位詞(hypernym)的路徑連接到一個根上位詞(root hypernym),如entity.n.01。因此兩個同根相連的synset可能會有幾個共同的上位詞。如果兩個 synset共享一個非常具體的上位詞(一個低層次的上位詞),那表示它們應該是密切相關的!(大概都是一些鯨魚的名稱,後面加入tortoise陸龜、vertebrate脊椎動物)
>>> right = wn.synset('right_whale.n.01') >>> orca = wn.synset('orca.n.01') >>> minke = wn.synset('minke_whale.n.01') >>> tortoise = wn.synset('tortoise.n.01') >>> novel = wn.synset('novel.n.01') >>> right.lowest_common_hypernyms(minke) [Synset('baleen_whale.n.01')] >>> right.lowest_common_hypernyms(orca) [Synset('whale.n.02')] >>> right.lowest_common_hypernyms(tortoise) [Synset('vertebrate.n.01')] >>> right.lowest_common_hypernyms(novel) [Synset('entity.n.01')] |
當然,我們知道「whale (鯨)」已經蠻具體了,但是「 baleen whale(鬚鯨)」更具體,然而「脊椎動物(vertebrate)」與「實體(entity)」則更具有一般性(general)。我們可以去量化這些synset的在概念階層裡面的深度:
| >>> wn.synset('baleen_whale.n.01').min_depth() 14 >>> wn.synset('whale.n.02').min_depth() 13 >>> wn.synset('vertebrate.n.01').min_depth() 8 >>> wn.synset('entity.n.01').min_depth() 0 |
從上面這麼豐富的介紹文後,你應該可以猜出我們到底想做什麼事情。沒錯!就是標題說到的「相似性測量(Similarity measure)」!舉例來說,透過「path_similarity()」來找到一個連結兩個概念的上位詞,而且這個上位詞是在整個階層概念中離兩者的最短路徑上,會產生一個0到1值來量化這個相似程度。如果完全沒有的話,這個值就會是「-1」,如果是完全相同的話,值就是「1」。最後我們來觀察一下這幾組字詞的相似程度: right whale、orca、ortoise、novel。雖然數字並不具有太大的意義,但是當它們從海洋生物一路比較到無生命物體時,明顯地這個相似性的值也是一路下滑的。
| >>> right.path_similarity(minke) 0.25 >>> right.path_similarity(orca) 0.16666666666666666 >>> right.path_similarity(tortoise) 0.076923076923076927 >>> right.path_similarity(novel) 0.043478260869565216 |
下一節:第三章 面對原始文本的處理方式(3.1 怎麼從網頁或硬碟存取文本資料)
2 則留言:
你好
請問你何時會寫第三章呢?
還有你知道要如何使用繁體中文檔案嗎?
謝謝
你好,因為本人目前當兵XDD
所以目前這部落格的內容不太會更新了,
如果有需要,可以直接去網站看:
http://www.nltk.org/book
中文文本的問題,可能要使用其他工具,
據我所知NLTK碰到中文只有一個慘字...
張貼留言